Matching
Lexer grammar can have multiple rules matching various tokens that can possibly appear on input stream. Lexer reads subsequent characters from input stream and tries to match them against all rules. If, after having read a few characters, some rules don't match current input sequence, lexers ignores such rules and continues operation for other rules that still give hope of match. Lexer continues the walk until no rule can match any more characters. Then it stops and reports rule that gave longest match.
Lexer operation principles can be summarized as follows:
- matching input always starts from certain point in input stream which is considered the current position.
- all grammar rules are checked against input (unless user decides to disable some of them explicitly by using modes)
- rule that gives longest match is reported
- if multiple rules give match of the same length, the one defined earlier in the grammar is reported
- when regular expression defined for a rule has variable-length element (like asterisk operator x*) lexer will try to expand match for such elements as much as possible (i.e. expression x* will try to match as many 'x'-s possible)
- after reporting a match current position in input stream is advanced to the end of that match. Next invocation of lexer will continue matching from new position onward. User can modify this behavior by moving current position backwards to any point within just reported match using LESS functionality.
- if input does not match any of the rules (i.e. single character at current position does not match start of any rule), an error is reported. If user decides to ignore this error and invokes lexer again, the lexer advances current position by one character before attempting next match. This prevents endless looping.
Above rules are illustrated using example (see Fig. 9 ).
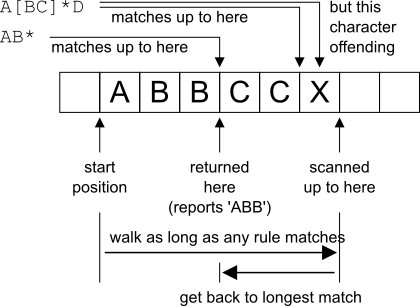
Using grammar with two rules:
AB*
With input text:
ABBCCX
When lexer starts reading input, both rules are plausible options.
After reading first three letters ABB both rules are still likely options. Rule AB* gives full match for this sequence and could be potentially reported as matching. Rule A[BC]*D does not match current input yet, since it requires terminal 'D', but it gives hope for longer match.
After next letter C, current input sequence becomes ABBC. This sequence does not match rule AB*, so lexer ignores that rule. However the other rule A[BC]*D still gives hope for match, so lexer continues the scan.
When letter X is reached, input sequence is ABBCCX. Rule A[BC]*D does not match it.
Lexer has to report a longest match. It gets back to rule that gave longest match so far but was abandoned in search for better match. In this case the rule giving longest valid match is AB* with value ABB. Lexer reports match for this rule.