Buffers
Lexer stores data in buffers. In general lexer can be using three buffers:
Input buffer
Input buffer is used to store raw input data, which, depending on configuration, is byte or character oriented. To improve performance lexer reads data in chunks and is best paired with block-oriented input stream.
Lexer buffer
Internal lexer buffer, if used, stores input text after decoding it to 4-byte double words. This buffer can be used to speed up operation if rescan of input characters is often used. If lexer buffer is not used, rescan is done using input buffer.
Output buffer
Output buffer stores value of current output token encoded in chosen output encoding. Since it must accommodate value of just a single token its size usually remains small.
Lexer can be configured to produce output value always, or on demand. In second case output value is calculated only when user attempts to get it. Assuming that values for certain tokens are never used (like text of comments in input file) this approach can result in better performance when lexer is configured to perform transcoding between input and output.
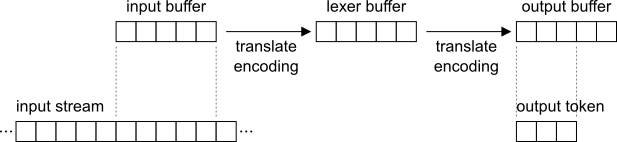
All three buffers are seldom used. Typical configuration includes two buffers: one for input and one for output. If lexer does not perform encoding translation single buffer can be sufficient.
Configuration of buffers used by lexer can be done in two ways:
- manually – user explicitly enables and disables particular buffers
- automatically – user selects required features and Alpag decides which buffers to use.
Automatic approach is preferred, unless user has some specific requirements supported by deep knowledge of lexer buffer organization.
Options for manually controlling lexer buffers are located in Lexer.Buffers group.
Many other options influence allocation of buffers. Most of them are in Lexer.In, Lexer.Out groups.