Automaton
Lexers generated by Alpag analyze input text using structure known as Deterministic Finite Automaton (DFA). In most cases there is no need to inspect structure of the automaton, since lexer behavior can be usually well predicted analyzing grammar alone.
Sometimes, when lexer behaves not as expected and grammar is very complex , user may be forced to analyze and understand structure of generated automaton. It is also inevitable if user wants to observe lexer activity in runtime.
Alpag can generate report containing structure of automaton.
- –lr option generates a textual report.
- –lrx option generates XML report which can be translated to HTML.
Understanding generated report requires some knowledge of automaton operation principle and its relationship to source grammar.
Automaton is described by a set of states. Transitions between states are triggered by input characters. Graph of transitions is fixed, and contains entire logic of lexer.
At any moment lexer is in a single particular state. Reading following input character triggers transition to next state in accordance with defined transitions. If no transition is defined for given input character, then input text read so far does not match defined grammar.
Some automaton states are marked as accepting. Reaching such states means, that input text processed so far fully matches some grammar rule. Lexer tries to get longest match possible, so it keeps reading following characters. When no more input characters can be matched, lexer returns to most recently visited accepting state and reports a match.
Lexer features a single automaton which accommodates all rules defined in grammar, and tries to match them in parallel during a single walk. Such automaton is a nontrivial sum of all automatons defined for individual rules, and may be hard to understand. The problem is illustrated on Fig. 10.
Left-upper part of Fig. 10 shows automaton for a single regular expression A[BC]*D. Automaton starts in state 1. The only transition in this state is under character A (any other character would cause automaton to fail). After A was read automaton goes to state 2. In this state any character B or C will cause transition back to state 2. Any number of B,C characters can be read this way. Reading D leads to state 4 which is also an accepting state.
Right-upper part of Fig. 10 shows automaton for expression AB*. State 2 in this automaton is an accepting state but it can take more occurrences of B to give longest match possible.
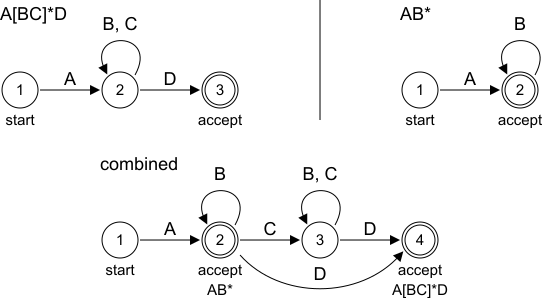
Bottom of Fig. 10 shows automaton which is combination of both elementary automatons. It has distinct accepting states for individual rules. In combined automaton state 2 corresponds to reading single A which is common for both rules A[BC]*D and AB*. After reading any number of letters B in this state both rules are still likely matches. A single encountered C moves lexer to state 3. In this state only viable option is expression A[BC]*D. Lexer will wait for first D to move to state 4 and report a match. If D is not encountered, lexer remembers having visited state 2 which is an accepting state for earlier match. It returns to this state and report a match for AB* rule.
Summary of lexer automaton generated by Alpag using –lr option is shown below (some elements removed). XML version of report generated with –lrx and converted to HTML can be found here.
Analyze automaton structure and compare it against graph shown on Fig. 10.
&1
regex: A[BC]*D
&2
regex: AB*
symbols
%1 symEOL
%2 elements: A
%3 elements: C
%4 elements: B
%5 elements: D
automaton
states
@1
goto @2 under %2 A
@2
accept &2
goto @3 under %3 C
goto @2 under %4 B
goto @4 under %5 D
@3
goto @3 under %3 C
%4 B
goto @4 under %5 D
@4
accept &1

When grammar contains many overlapping rules with similar prefixes automaton structure can be very complex. If rules differ (preferably by means of their initial parts) combined automaton is usually simple.